


Hi #GetFediHired, I'm looking for a #remote role in the US (or #sweden if you provide visa assistance!).
I've worked mostly in #SoftwareEngineering space, but I do lean closer to the #DataEngineering side of things (past 3 years). Before that I was varying levels of doing SWE things inside a #BusinessIntelligence role (~5 years).
Looking for something that demands strong #Python skills (~5+ years of heavy, daily use), though wouldn't mind having to learn something new. Quite comfortable in a few #SQL flavors. I can actually read most #regex, if that's a thing worth bragging about. Love writing #xpath in personal webscraping projects. Somewhat familiar with #SpringBoot and #Kotlin (1 year, occasional) and would like to eventually use more Java in work, but not a hard requirement.
I love refactoring/improving old code, and I have lots of experience with CI/CD, coding best practices, testing, web scraping, backend (Flask) & frontend (React, Typescript).
Send me a message if this sounds like I'd be a great fit on your team!

 Because that quickly leads to data redundancy, anomalies, and integrity issues when inserting, updating, or deleting records.
Because that quickly leads to data redundancy, anomalies, and integrity issues when inserting, updating, or deleting records.

 Ep. 2 of
Ep. 2 of  Listen at
Listen at 





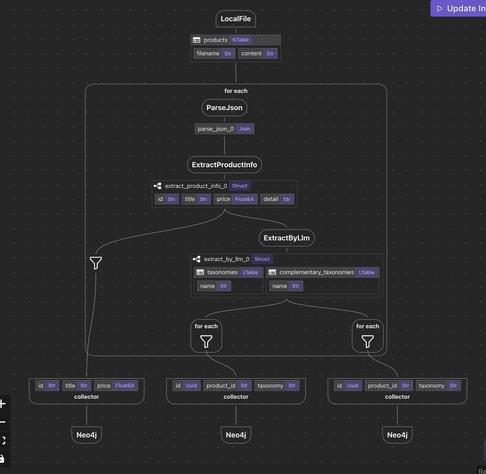
 Open Source of the Week - The dagster project
Open Source of the Week - The dagster project  Join 29k subscribers and subscribe to get weekly updates
Join 29k subscribers and subscribe to get weekly updates 




 One does not simply build reports on OLTP data…
One does not simply build reports on OLTP data… This session is packed with:
This session is packed with: Whether you’re a data wizard
Whether you’re a data wizard  , business hobbit
, business hobbit  , or SQL ranger
, or SQL ranger  — this is your quest.
— this is your quest. Join us LIVE on LinkedIn | Wednesday, July 2nd @ 2PM Central
Join us LIVE on LinkedIn | Wednesday, July 2nd @ 2PM Central




 Project link on
Project link on 

 P.S. Found this helpful? Tap Follow for more cybersecurity tips and insights! I share weekly content for professionals and people who want to get into cyber. Happy hacking
P.S. Found this helpful? Tap Follow for more cybersecurity tips and insights! I share weekly content for professionals and people who want to get into cyber. Happy hacking 



 New Slides
New Slides 



 RT plz
RT plz